人工智能领域正迎来新的突破性进展。2024年1月20日晚,中国科技公司DeepSeek(深度求索)正式发布了其最新推理模型DeepSeek-R1,引发业界广泛关注。这款模型不仅在性能上与OpenAI的GPT-4相媲美,更以其开源策略和创新的训练方法,为AI发展带来了新的可能性。
DeepSeek-R1的核心特点在于其独特的训练方法。与传统模型不同,DeepSeek-R1大规模应用了强化学习技术,特别是在后训练阶段。这种方法允许模型在极少量标注数据的情况下,通过自主学习和优化来提升推理能力。强化学习的应用使得DeepSeek-R1能够像人类一样通过”试错”来学习,这不仅提高了模型的性能,还大大降低了对大量预先标注数据的依赖,从而降低了训练成本。
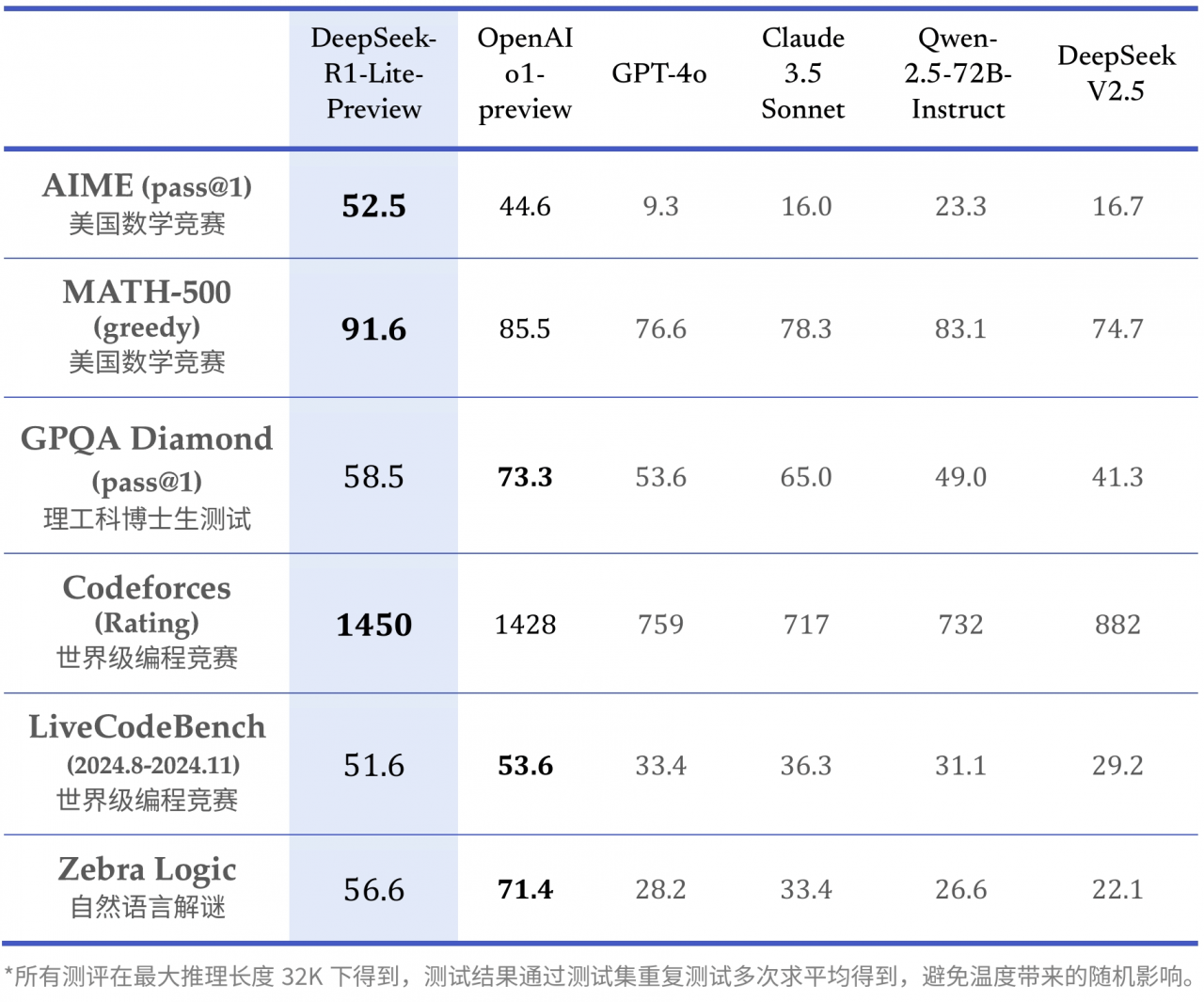
在性能方面,DeepSeek-R1展现出令人瞩目的实力。官方数据显示,在数学、代码和自然语言推理等任务上,DeepSeek-R1的表现与OpenAI的GPT-4旗鼓相当。特别是在美国数学邀请考试(AIME)中,DeepSeek-R1-Zero版本的得分高达86.7%,超越了OpenAI的同类产品。在Codeforces编程竞赛中,DeepSeek-R1的Elo评分达到2029,超过了96.3%的人类程序员。这些数据充分证明了DeepSeek-R1在复杂推理任务上的卓越能力。
DeepSeek-R1的另一大亮点是其开放策略。该模型采用MIT许可证开源,允许用户自由使用、修改,甚至可以利用DeepSeek-R1来训练其他模型。这种开放态度不仅体现了DeepSeek公司的技术自信,也为整个AI社区带来了宝贵的资源。此外,DeepSeek还开源了包括32B和70B在内的多个小型模型,这些模型在多项能力上直接对标OpenAI的GPT-4-mini,为开发者提供了更多选择。
在实际应用中,DeepSeek-R1展现出了令人印象深刻的能力。据报道,这款模型能在80秒内完成一道高考压轴题,9分钟内写出一段解释量子力学概念的动画代码。它不仅擅长理科题目,在人文学科方面也表现出色,能迅速回答脑筋急转弯,并深入分析历史细节。这种全面的能力使DeepSeek-R1成为一个真正的多才多艺的AI助手。
DeepSeek-R1的定价策略也颇具竞争力。与OpenAI的API相比,DeepSeek-R1的使用成本大幅降低。每百万输入tokens仅需1元人民币(缓存命中时),输出tokens为16元,这一价格优势无疑会吸引更多开发者和企业用户。
然而,尽管DeepSeek-R1展现出了令人惊叹的能力,但它仍然存在一些局限性。例如,在语言表达的可读性和流畅性方面还有提升空间。此外,由于大量使用强化学习,模型的决策过程有时难以解释,这可能在某些应用场景中成为一个挑战。
DeepSeek-R1的发布标志着中国在AI领域的重要突破。它不仅展示了中国企业在技术创新方面的实力,也为全球AI发展提供了新的思路。通过开源策略和创新的训练方法,DeepSeek-R1为AI的民主化和普及化做出了重要贡献。随着更多开发者和研究者参与到这个开放生态系统中,我们有理由期待在不久的将来,AI技术将在更广泛的领域中发挥更大的作用。
AI模型DeepSeek-R1的发布引发了业界广泛关注。这款模型以其强大的性能、创新的训练方法和开放的策略,展现了中国在AI领域的技术实力。DeepSeek-R1在数学、编程和自然语言处理等多个领域表现出色,与国际顶级模型相媲美。其开源策略和具竞争力的定价为开发者和企业用户提供了新的选择。尽管在某些方面仍有改进空间,但DeepSeek-R1的出现无疑为全球AI发展注入了新的活力。














请登录之后再进行评论